【概要ご紹介】研究論文「汎用性を志向したWikipediaエントリへの拡張固有表現付与」 前編
最終更新日:2023年6月12日

こんにちは。ホットリンクR&Dの榊です。本日は、前回に引き続き弊社R&D部が発表した論文の内容についてご紹介します。
(おかげさまで、下期からR&DグループはR&D部に昇格いたしました。ただし、業務内容は全く変わっておりません(笑))
先日、6月9、10日に鳥取大学で開催された言語理解とコミュニケーション研究会で、開発途中の技術について「汎用性を志向したWikipediaエントリへの拡張固有表現付与」というタイトルで発表してきました。
電子情報通信学会 講演論文詳細
http://www.ieice.org/ken/paper/20170610FbuG/
本日は、こちらの論文概要について前後編に分けてご紹介したいと思います。
なお、今回も「詳細は論文をご参照ください」と言いたいところなのですが、電子情報通信学会(IEICE)ではまだ当該論文を公開しておりません。
御用の方は、IEICEのオンライン技報サービスにご登録いただくか、弊社R&D部までお問い合わせください。
論文概要を短縮版でご紹介
まず、論文概要の大きな流れをお伝えしたいと思います。
【問題設定】
「任意の単語に対して、その語に関する情報を用いて固有表現の区分を推定する手法」の開発に取り組む。このような技術を実現できると、例えば、大量の新語・未知語がある場合に,提案手法で語のジャンルを自動推定することで、人手をかけることなく業種(ドメイン)別の辞書を構築することができるようになる。

【分類方法と正解データ】
ドメイン辞書を構築するために、「関根の拡張固有表現階層」という固有名詞(固有表現)の分類クラスに、新語・未知語を自動分類することを目指す。(関根の拡張固有表現階層を、そのままドメインとして用いる)。正解データとしては、関根の固有表現分類階層を、Wikipediaのエントリに人手で付与したデータセット「拡張固有表現+Wikipedia」を用いる。
【提案手法】
下記のようなニューラルネットワークを学習し、それを単語の固有表現クラスへの分類として用いる。
入力:単語を特徴ベクトル化したもの
出力:固有表現クラス、付与されるべき固有表現のクラス数
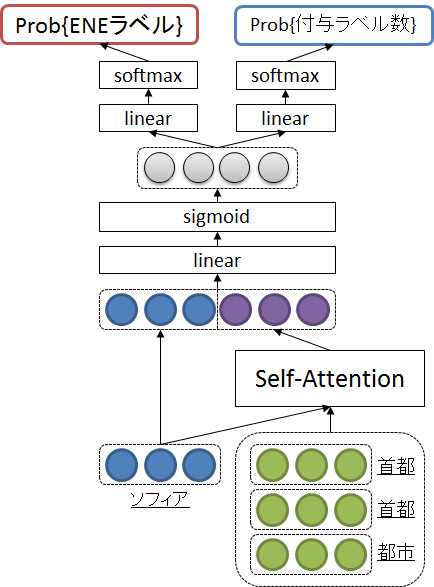
ここで工夫したのは「Wikipediaに特有の特徴量は用いない」点。Wikipediaに特有の特徴量を用いると、Wikipediaに出現しない新語・未知語が扱えなくなるため(先行研究では、Wikipediaに特有の特徴量を用いている。)
【評価実験】
先行研究と比較して、微量ながら性能が改善した。実用上ではほとんど変わらない程度の改善である。ただし、提案手法では、Wikipediaに出現しない語でも対象とすることができるため、先行研究よりも汎用性が高い。
それではここからは順を追って、【問題設定】【分類方法と正解データ】【提案手法】【評価実験】についてさらに詳細に解説いたします。本日は前編として前2者をとりあげ、明日のブログで残りの2トピックをご紹介します。
問題設定
皆さん「固有表現」というものはご存知でしょうか? 「固有表現」とは、いわゆる特定の実体(エンティティ)を表す固有名詞(人名、地名、組織名)および、日付や時間表現などのことを指します。これらの固有表現をテキスト中から抽出することができれば、特定の人や地域、特定の日付に言及したテキストを特定し、さらにその情報を抽出することが可能になります。
このような課題は、NLPでは「固有表現抽出」と呼ばれ、古くから研究されてきました。ソーシャルメディア分析における固有表現抽出のビジネス応用を考えると、例えば特定の商品(コカ・コーラ)に言及した投稿を収集する、特定の商品ジャンル(例:飲料)に言及した投稿を収集する、などが考えられます。
一見するとこの課題は、固有名詞を集めた辞書を人手で整備すれば解決できるように感じるかもしれませんが、それだけでは残念ながら不十分です。ビジネスの分野、特にソーシャルメディア上では、新たな固有名詞や略称が日々無数に生み出されています。たとえばビジネス上の固有名詞ともいえる「商標」を考えてみると、1年あたりの出願数は約16万件にも上ります[特許庁]。既知の情報を集約した辞書に頼るのみでは不十分であり、未知の単語であっても自動的に固有表現を認識し、分類できる仕組みが必要である、ということがわかります。
そこで本研究では「任意の単語に対して、その語に関する情報を用いて固有表現の区分を推定する手法」という課題に取り組むこととしました。
図1 単語リストの分類によるドメイン辞書の自動構築
分類方法およびデータセット
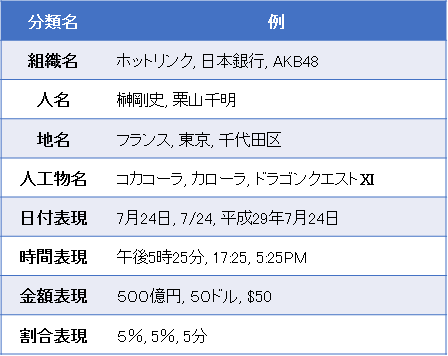
まず、本研究で用いた固有表現の分類とデータセットについて紹介します。固有表現抽出に関する研究では、IREXと呼ばれる分類体系の利用が一般的です[IREX 99] 。表1に区分および分類例を示します。しかし、クルマもゲームソフトも飲料も「人工物名」では、ちょっと困りますよね。ビジネス目的であれば、もっと細かい分類体系を使いたいことが多いでしょう。我々も同じように考えました。
表1 固有表現の分類体系:IREX
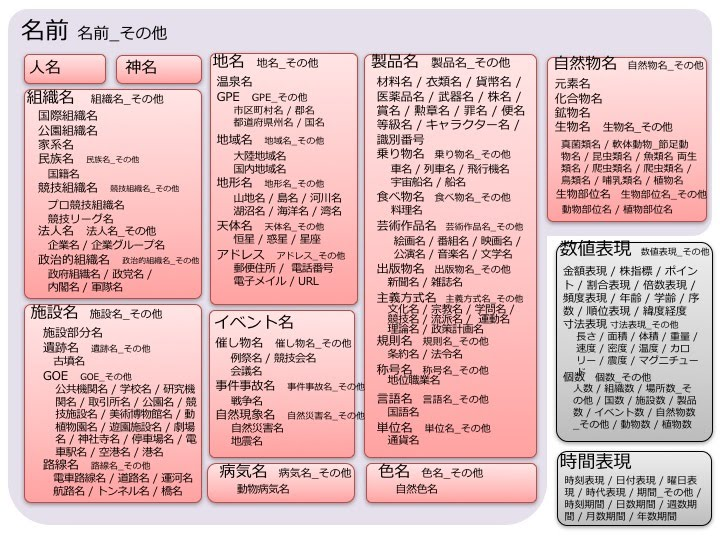
そこで本研究では、関根の拡張固有表現階層(Extended Named Entity = ENE)と呼ばれる分類体系を用いました[Sekine 08]。図2に分類体系を示します。ENEの長所としては、区分数が多いこと(約200区分)および、区分が階層化されているため粒度が調整できるという点が挙げられます。ENEは百科事典を参考にして作られたものだと伺っていますが、ビジネス用途全般においても、使い易い分類体系であると思います。
図2 関根の拡張固有表現階層
画像の出典:https://sites.google.com/site/extendednamedentity711/
分類体系を選んだら、あとはデータセットが必要です。ありがたいことに先行研究では、WikipediaのエントリにENE区分を人手で付与したデータセット「拡張固有表現+Wikipedia」 が構築されています[関根+ 16]。このデータセットを用いると、記事見出し語とENE区分の組み合わせ、たとえば「サツマイモ => 食べ物名_その他、植物名」といった組み合わせを収集することができます。本研究では、こちらを学習・評価用のデータセットとして用いました。
以上、前半では「問題設定」と「分類方法およびデータセット」についてご紹介しました。後半では、「提案手法」「評価実験例」をご紹介したいと思います。明日のブログもお楽しみに!
参考文献
[特許庁] 特許庁, 特許出願等統計速報.
https://www.jpo.go.jp/shiryou/toukei/syutugan_toukei_sokuho.htm
[IREX 99] Information Retrieval and Extraction Exercise. http://nlp.cs.nyu.edu/irex/NE/
[Sekine 08] Extended Named Entity Ontology with Attribute Information. LREC08
[関根+ 16] 「拡張固有表表現+Wikipedia」データ. 言語処理学会第22回年次大会(NLP2016), March 2016.http://www.languagecraft.com/enew/
【概要ご紹介】特選論文にも選出された共著論文「バースト現象におけるトピック分析」前編
【概要ご紹介】特選論文にも選出された共著論文「バースト現象におけるトピック分析」後編
「AKB48の計算社会科学」イベントレポート前編 ~やっぱり現役アイドルはすごかった、そのプレゼン力に完敗~
「AKB48の計算社会科学」イベントレポート後編 ~アイドルがファンを獲得するにはソーシャルメディア上でどう振る舞うべき?~
ホットリンクで一緒に働きませんか!!
ホットリンクでは、SNSコンサルタントやSNSプロモーションプランナーなど、さまざまなポジションで一緒に働くメンバーを募集しています!



人気記事ランキング





最新の記事


X(旧Twitter), Instagramマーケティングについてお悩みの方へ
プロ視点の解決策をご提案いたします!まずはお気軽にご相談ください
