≪テキストマイニングエンジニア向け≫大規模辞書マッチングを手軽に高速化してみた
最終更新日:2023年6月12日
開発本部研究開発グループR&Dチームのサンティです。
(サンティさんの紹介はこちらから:≪社員紹介≫ホットリンクのサービス基盤技術を長年に渡って支える屋台骨)
今回は、テキストマイニングのエンジニア向けに、ホットリンクで研究開発を進める過程で、調査・整理した技術的な内容を紹介します。だいぶ技術寄り、しかも自然言語処理の分野の話ですので、一部の読者の方々は置いてきぼりになってしまうかもしれません。その点は、ご了承頂ければと思います。
さて、皆さんは“Dictionary Matching”という技術をご存知でしょうか?
Dictionary Matchingとは入力テキストの中に、予め登録しておいた文字列パターンの集合(辞書)と一致する部分を特定する技術です。辞書をベースとした固有名詞認識のようなサービスに使われています。
例えば、「東京特許許可局へ行きました。」をMecabで分かち書きすると、下記のように分解されます。
「東京 特許 許可 局 へ 行き まし た 。」
しかし、ここはちゃんと「東京特許許可局」という局名として認識して欲しいところですね。Dictionary Matching機能を利用する場合、予め固有名詞辞書に「東京特許許可局」をカスタム辞書に登録しておくと下記のように出力されます。
「東京特許許可局 へ 行き まし た 。」
スッキリして、分析しやすくなったのが分かると思います。
ここでいうカスタム辞書に登録されている単語数が数十、数百単語程度の場合はあまり問題になりませんが、数十万、数百万単語になりますと様々な支障が生じ、簡単には実装できなくなってしまいます。本ブログでは、便宜上、数百万単語でDictionary Matchingを行う場合にBig Dictionary Matchingと名付けます。
昨今、インバウンド市場を賑わせている中国人観光客のおかげで、我々R&Dグループに中国語の自然言語処理のお仕事が回ってきました。分析対象は中国語SNSの投稿文です。既存の自然言語処理のツールは、大抵、正確で綺麗な文書の分析を目的として作られているため、オープンソースのツールやパッケージでは対応しきれない部分が多々あり、自社で様々な補強作業が必要となります。
そこで、自社中国分析ツール開発の過程で、固有名詞辞書機能、特に大規模な辞書を対象としたBig Dictionary Matchingの手法が必要となりました。一見簡単そうに思えましたが、実際にやってみると色々と失敗を繰り返し、少量のメモリかつ高速で辞書マッチングを行うのが結構難しいとつくづく気付かされました。しかし、Web上には該当する良い資料が見つかりませんでした。今回はその試行錯誤と解決への道で得られた知見をご紹介します。
目標は、『約350万語を収録した固有名詞辞書を参考にしながら、任意の中国語文章の中にあるすべての固有名詞を特定すること!』 皆さんならどうしますか?
コンピューターサイエンスにおいては、解決したい課題に対して、データの表現をうまく転換することで、簡単に解決できる例が多々あります。今回の課題では、利用するデータ構造によって異なる様々なメリット・デメリットが考えられました。私が知る限り、昔から辞書マッチングの場合は正規表現をはじめ、Trie、Patricia Trie、Directed Acyclic Word Graph (DAWG)、Aho-Corasickなど、それぞれの特徴や性能が異なりますが、いずれにせよこれらのアルゴリズムで対応できそうだと分かりました。

ところが 正規表現、Trie、 Patricia Trie、Aho-Corasickを試してみましたが、ことごとくメモリ使用量が爆発してしまいました。紆余曲折は省きますが、最終的には物理的なメモリ量問題にぶち当たり、撃沈してしまいました。ただひとつ救いだったのは、DAWGデータ構造でした。これなら、なんとか要求に応えられて機能します。重いモジュールという事実は変わらないのですが、DAWGに感謝です。

次に、実際に選定したデータ構造を実装しますが、こちらも多数の選択肢があります。調査の結果、速度と省メモリの両方を実現できるのは、Doubly Arrayであることが分かりました。そこで、今回はDAWGをDouble Arrayで実装することとしました。

なお、余談ですが、世の中では高精度かつ高速な形態素解析ツール「Mecab」の右に出るものはありません。精度か速度をどちらかをトレードオフしない限り、Mecabに勝ることは困難です。ソースコードを見る限り、そのMecabに採用されている辞書マッチング技術は先ほど紹介したDouble Array Trieのようです。
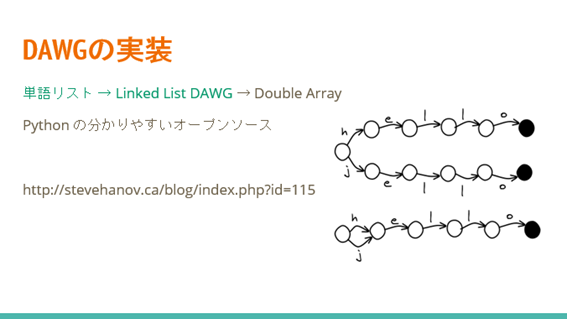
ところで、Double Array DAWGについて、これと言ったオープンソースが見つからないので仕方なく自分でなんとかすることにしました。調べたところ、上記のサイトが分かりやすくPythonコードもあるのでDAWG部分を真似してみます。
今回は、個人的な好みによりJulia言語を用いて,DAWGの実装を行いました。勉強しながら進めたので結構苦労しましたが、DAWGとDouble-Arrayの実装が完成した時は本当に嬉しかったです。

さて、気になる性能を測ってみたら表のようになっています。メモリ使用量が小さく、分析速度もなかなか高速でした。一般のCPUの1コアで3万文/秒を超えています。 データセットの詳細は言及しませんが、実務上で引っ張ってきたものです。

ちょうどJulia言語にはSparse Matrixが標準装備されています。詳細は省きますが、この行列の種類はスカスカな行列に強く、巨大な行列でもデータがスカスカな場合は、省メモリで行列の形で利用可能です。行列と言えば表形式そのものなため、この技術を使えば、メモリとスピードのトレードオフが必要なくなるではないかと期待していました。 もう一頑張り、Sparse Matrix を使ったDAWGを実装することにしました。

その結果、さすがSparse Matrix!期待通りのスピード改善が観測できました。データ構造の作成時間が大幅縮小!Double-Arrayに比べ、12分のところがたった1分程度に短縮できました。メモリ使用量はDouble-Arrayより少し大きいですが、75%ほどのスピード改善でこれくらいのメモリ量はほぼ無視できます。
結果的にSparse Matrix DAWGの方が圧倒的に強いコンビだということが分かりました。 Sparse MatrixはJulia言語に限らず、RやPythonでも装備されています。むしろ、そちらの方が主流w 最強ではないかもしれませんが、今後、大規模辞書マッチングを手軽に高速化する機会があったらどうぞSparse Matrix DAWGを試してみてください。
今回の記事のより詳細な内容が知りたい方は、
今回は、テキストマイニングのエンジニア向けに、かなり専門的な記事を書かせていただきました。今後も、ホットリンクでは、データマイニング・人工知能分野のエンジニアや研究者の方々に役立つような情報を発信していきたいと考えています。
ホットリンクで一緒に働きませんか!!
ホットリンクでは、SNSコンサルタントやSNSプロモーションプランナーなど、さまざまなポジションで一緒に働くメンバーを募集しています!
人気記事ランキング




最新の記事
-
【5月15日開催】25卒向け|新卒社員が語る! SNSマーケティングコンサルってどんな仕事?2024年04月09日

-
【4月24日開催】25卒向け|新卒社員が語る! SNSマーケティングコンサルってどんな仕事?2024年04月09日

-
求む!愛を持ってお客様に接するカスタマーサクセス。顧客理解のカギは、好奇心&洞察力 #ホットピ 2024年03月26日

-
ホットリンクで描く、若手のキャリアアップストーリー。新卒・第二新卒社員が見つけた夢とは #ホットピ2024年02月26日

-
ユーザーに楽しまれるデザインの裏側。ホットリンクのSNSデザイナーの醍醐味と大切にしている仕事ルール #ホットピ2024年02月16日

Twitter, Instagramマーケティングについてお悩みの方へ
プロ視点の解決策をご提案いたします!まずはお気軽にご相談ください
