【概要ご紹介】研究論文「汎用性を志向したWikipediaエントリへの拡張固有表現付与」 後編
最終更新日:2023年6月12日

こんにちは。R&Dの榊です。
先日、6月9、10日に鳥取大学で開催の言語理解とコミュニケーション研究会で発表した、開発途中の技術についての論文「汎用性を志向したWikipediaエントリへの拡張固有表現付与」の概要を前後編に分けてご紹介しています。
電子情報通信学会 講演論文詳細
http://www.ieice.org/ken/paper/20170610FbuG/
前半では「問題設定」と「分類方法およびデータセット」についてのご紹介でした。後半の本日は、「提案手法」「評価実験例」です!是非ご覧ください。
提案手法
提案手法の説明に入る前に、本研究が対象とする問題の特徴を簡単に述べます。
一つ目は「多クラス分類である」ということです。「サツマイモ => 食べ物名_その他、植物名」で例示したように、単語によっては複数のENE区分を持ちます。従って、ひとつのデータが2つ以上のクラスに分類されうる、という問題になっています。
二つ目は「Wikipedia記事に固有でない情報のみを、分類の手がかりに利用する」ということです。Wikipedia記事には、カテゴリ情報や記事間のリンク関係など、ENE区分を推定するために有用と思われる手がかりが多数含まれていますがWikipediaに未収録の単語が相手の場合、これらの手がかりは当然ながら入手できません。
本研究では「任意の単語に適用できる手法」を志向しますので、こうした手がかりを利用しない、という制約を課しています。
特徴量
分類問題で重要なのは「どのような手がかりを用いるか」すなわち特徴量の選定です。本研究では 1)見出し語 2)見出し語の疑似上位語セット の2つを、それぞれ単語分散表現[Bojanowski+ 16]に変換したものを用いました。
- 見出し語
ENEラベルを推定したい単語そのものです。「拡張固有表現+Wikipedia」データセットの場合は、Wikipedia記事のタイトルと同義です。 - 見出し語の擬似上位語セット
見出し語の「上位概念に対応する語」の集合です(例:サツマイモ => 野菜、食べ物、植物)。ただし上位語とは言えない語が混在してもOKとしています(なので「疑似」と付けている)。上位語の獲得元ですが、Wikipedia見出し語の場合は当該記事の説明文から獲得します。Wikipediaに未収録の単語の場合は、大規模テキストから自動獲得する想定です(本研究では前者の場合のみを検証しています)。

図3 特徴量の例:「ソフィア(ブルガリアの地名)」
分類器の生成
本研究では、2入力✕2出力・3層ニューラルネットワークを用いました。図4に模式図を示します。入力層には(前述のとおり)対象の単語および0個以上の疑似上位語セットを入力します。これに対して出力層は2種類の情報を出力します。1つは固有表現クラス(Prob{ENEラベル})です。こちらは各クラスへの分類確率を出力します。もう一つは、付与ラベル数(Prob{付与ラベル数})です。単語によっては複数の固有表現クラスに分類されるため、いくつに分類するのが適切かを出力します。予測時には、出力された付与ラベル数をNとして、分類確率が上位N個のENEラベルが付与されます。
また、提案手法では、「Self-Attention Mechanism」という仕組みを導入しています[Lin+ 17]。詳細は解説しませんが、この仕組みは(誤って入ってくる)上位語とは言えない語の影響を弱めることを狙いとして導入したものです。定性的に検証した限りでは、狙い通りの振る舞いが学習されることを確認しています。
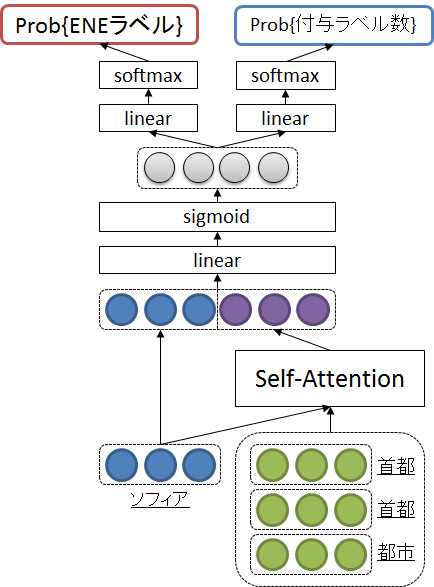
図4 提案手法:2入力✕2出力・3層ニューラルネットワークの模式図
評価実験
評価方法
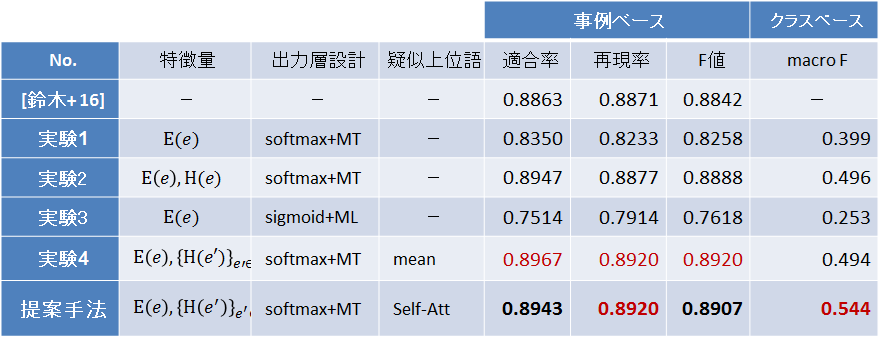
評価実験では、特徴量、出力層、疑似上位語セットの処理方法それぞれを変更した5つの実験パターンを作成し、既存研究[鈴木+ 16]も含めた性能評価を行いました(図5)。
実験結果
実験結果は表2のようになりました。提案手法は、事例ベースのF値で 0.89 を実現し、先行研究[鈴木+ 16]を0.6ポイント上回りました。また実験パターンの中では、提案手法が最も高い性能を得ています。
先行研究に対する優位性を考えると、分類性能は無視しうる程度の差です。しかし提案手法は、原理的にWikipediaの未収録語にも適用可能であるため、汎用性に優れていると考えています。
表2 評価実験結果
おわりに
今回は「拡張固有表現+Wikipedia」データセットを用いた性能評価のみを行いました。今後は実際にWebテキストから収集した単語を用いて、本来の目的であるドメイン辞書の自動構築タスクに取り組む予定です。
弊社R&D部では、実用上の要請に即した各種課題について、継続的に研究を行っています。本研究ではディープラーニングの手法を採用しましたが、特定の方法論に固執せず、課題に適した手法を用いる姿勢を是としています。また研究により開発された手法や知見は、新サービスの創出および継続的な改善に用いるため、積極的に実システムへの組み込みを行っています。
弊社R&D部における研究開発や、研究成果を用いたシステム開発に興味のある方は、本記事と併せて、下記の人材募集もご覧いただければ幸いです。
▼ホットリンク R&D部では下記職種を募集しています!ご興味ある方は是非ご応募ください▼
採用情報:リサーチプログラマ(募集人員 1名)
参考文献
[鈴木+ 16] Wikipedia 記事に対する拡張固有表現ラベルの多重付与. 言語処理学会第22回年次大会(NLP2016), March 2016.
[Bojanowski+ 16] BOJANOWSKI, Piotr, et al. Enriching word vectors with subword information. arXiv preprint arXiv:1607.04606, 2016.https://github.com/facebookresearch/fastText
[Lin+ 17] A Structured Self-attentive Sentence Embedding. arXiv preprint arXiv:1703.03130, 2017.
ホットリンクで一緒に働きませんか!!
ホットリンクでは、SNSコンサルタントやSNSプロモーションプランナーなど、さまざまなポジションで一緒に働くメンバーを募集しています!
人気記事ランキング





最新の記事
-
【5月15日開催】採用イベント「(25卒対象)新卒社員が語る! SNSマーケティングコンサルってどんな仕事?」2024年04月09日

-
【4月24日開催】採用イベント「(25卒対象)新卒社員が語る! SNSマーケティングコンサルってどんな仕事?」2024年04月09日

-
求む!愛を持ってお客様に接するカスタマーサクセス。顧客理解のカギは、好奇心&洞察力 #ホットピ 2024年03月26日

-
ホットリンクで描く、若手のキャリアアップストーリー。新卒・第二新卒社員が見つけた夢とは #ホットピ2024年02月26日

-
ユーザーに楽しまれるデザインの裏側。ホットリンクのSNSデザイナーの醍醐味と大切にしている仕事ルール #ホットピ2024年02月16日

Twitter, Instagramマーケティングについてお悩みの方へ
プロ視点の解決策をご提案いたします!まずはお気軽にご相談ください
